PR
私が使っているPCガジェット類
作業環境で実際に使っている・気になっている周辺機器などをまとめました
※ 一部のリンクは広告(アフィリエイト)を含みます
作業環境で実際に使っている・気になっている周辺機器などをまとめました
※ 一部のリンクは広告(アフィリエイト)を含みます
Seleniumで一番よく使うのが、要素を探すfind_elementとfind_elementsですよね、ブラウザを自動操作するときは、画面上のボタンや入力欄を「どうやって特定するか」がそのまま安定度に効いてきます
この記事はfind_element の使い方=「Byの選び方」と「エラーの回避」が主役です、CSSセレクタの書き方そのもの(属性・結合子・nth-childなどの一覧)は別記事「CSSセレクタの書き方 自動化で要素を狙う指定方法」にまとめたので、書き方を深掘りしたいときはそちらをどうぞ
まずはよくある基本の書き方です
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com")
element = driver.find_element(By.ID, "username")このようにBy.IDやBy.NAMEなどを使って要素を探します、1件だけならfind_element、当てはまる要素を全部リストで取りたいときはfind_elementsです
でも、このByの選び方によって、コードの安定性や書きやすさが全然変わってきます
Byの種類は実は結構な数がありまして、こんな感じです
ネットでは By.ID や By.CLASS_NAME もよく見かけますが、結論は By.CSS_SELECTOR を使っておけば間違いないです
もう一つの候補が By.XPATH ですが、CSS_SELECTORはスクレイピングで使うBeautiful Soupにも応用できますし、記述がすっきりしてわかりやすいので、こちらに軍配が上がります
CSS_SELECTORが最適な一番の理由は、他のByを全部CSS_SELECTORで代用できるところにあります
つまり、CSS_SELECTORさえ覚えてしまえば、他を使う必要がなくなるんです
ここからは、各Byを CSS_SELECTOR に書き換えるとどうなるかの一覧です、find_element(By.◯◯, ‘値’) の◯◯と値が、CSS_SELECTORならこう書けます(XPATHも参考に並べました)
| 探したいもの | 普通のBy指定 | CSS_SELECTOR一本だと | XPATH(参考) |
|---|---|---|---|
| id | By.ID, ‘hoge’ | ‘#hoge’ | ‘//*[@id=”hoge”]’ |
| class | By.CLASS_NAME, ‘hoge’ | ‘.hoge’ | ‘//*[@class=”hoge”]’ |
| タグ | By.TAG_NAME, ‘div’ | ‘div’ | ‘//div’ |
| name属性 | By.NAME, ‘hoge’ | ‘[name=”hoge”]’ | ‘//*[@name=”hoge”]’ |
| その他の属性 | 専用のByなし | ‘[data-test=”hoge”]’ | ‘//*[@data-test=”hoge”]’ |
| 複数クラス | 専用のByなし | ‘div.hoge.piyo’ | ‘//div[contains(@class,”hoge”) and contains(@class,”piyo”)]’ |
ひとつ例外があって、リンクを文字(テキスト)で探す By.LINK_TEXT / By.PARTIAL_LINK_TEXT だけは、CSS_SELECTORに「文字で探す」書き方がありません、その場合は aタグを集めて for でテキスト一致させると同じことができます
# テキストが完全一致するリンク(By.LINK_TEXT 相当)
next((a for a in driver.find_elements(By.CSS_SELECTOR, 'a') if a.text == 'hoge'), None)
# テキストが部分一致するリンク(By.PARTIAL_LINK_TEXT 相当)
next((a for a in driver.find_elements(By.CSS_SELECTOR, 'a') if 'hoge' in a.text), None)CSS_SELECTORのもう一つの大きな強みが、親子要素・兄弟要素をたどって一意に指定できるところです
親子・兄弟というのは、HTMLソースで見たときの縦・横の関係です

例えば上の図で黄色く囲った説明文2ですの要素を取りたいとき、クラス名だけで指定すると
driver.find_element(By.CLASS_NAME, "description")上にある「説明文です」の方を先に拾ってしまいます(n番目で指定する手もありますが、ややこしくなるので割愛します)
うまく取るには、指定が一意になるよう親要素からたどります、どこまで丁寧に書くかですが
などで取れます
ここで使った スペース(子孫)や >(直下の子)といった結合子は、隣接(+)や兄弟(~)も含めて種類があります、結合子の一覧と使い分けは別記事「CSSセレクタの書き方」の結合子の節にまとめたので、引き出しを増やしたいときはどうぞ
※このページの下部に同じ画像とサンプルHTMLを置いてあるので、実際に試してみてください
慣れればソースを見て起点の要素と狙った要素までの道のりが判断できるようになりますが、最初のうちは開発者ツール(DevTools)に下書きさせると早いです
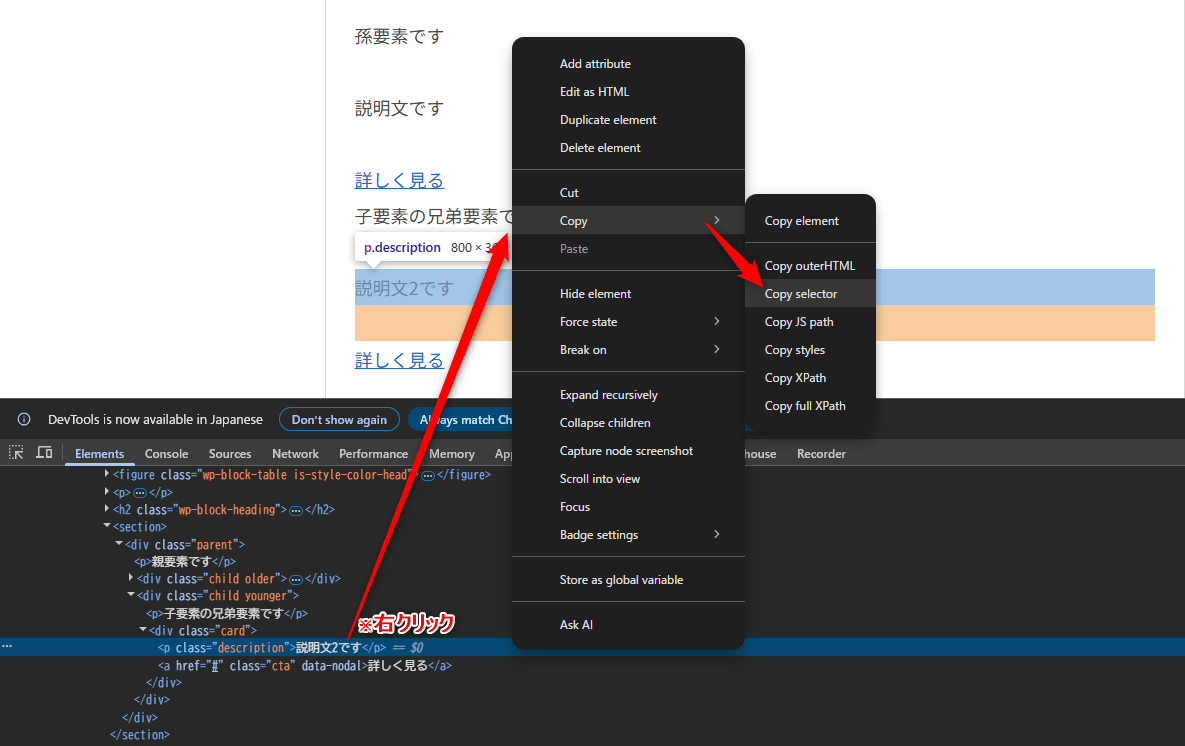
右クリックのCopy → Copy selectorでセレクタを取得できます、ただそのまま使うには長くて壊れやすいことも多いので、下書きとして受け取って自分で短く整えるのがおすすめです
Seleniumを触っているとよく出会うのが NoSuchElementException や ElementNotInteractableException です
要素が見つからなかったり、まだ読み込みが終わっていないのが原因です
例えば画面の文字を取得するとき、素直に書くとこうなりますが
hoge = driver.find_element(By.CSS_SELECTOR, '#hoge').textただ、これだと指定した要素が見つからなかったときにエラーで止まってしまいます
それを防ぐには、次の2パターンのどちらかがおすすめです
# 10秒待っても要素が見つからないエラーをキャッチする
try:
elm = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#hoge')))
hoge = elm.text
except TimeoutException:
print('#hoge が見つかりませんでした')
except Exception:
print('予期せぬエラーが発生しました')# 要素が見つからないとNoneを返す
elm = next((e for e in driver.find_elements(By.CSS_SELECTOR, '#hoge')), None)
if elm:
hoge = elm.text
else:
print('#hoge が見つかりませんでした')やり方は違いますが、どちらも「まず要素を検索」してから「目的のアクションを実行」することでエラーを防いでいます
このやり方なら、文字の取得だけでなく、文字入力やクリックにもそのまま流用できます
1つ目の WebDriverWait は奥が深くて、何を待つか(expected_conditions)の選び方で安定感が変わります、待ちでつまづいたら別記事「Seleniumで要素を確実に待つ方法」に詳しくまとめたので、あわせてどうぞ
基礎の基礎に見える find_element でも、Byの選び方やエラー回避まで含めると結構奥が深いです
少しずつ理解を深めて、Seleniumを活用していきたいですね
あわせて読みたい記事も置いておきます
最後に、練習に使えるHTMLを置いておきますので、ご自由にどうぞ
下のサンプルはこのページに実際に表示されています、開発者ツールで構造を見ながら、上で紹介したセレクタを試してみてください
PythonとExcelを中心に仕事に役立つ業務ツールや自動化、スクレイピングツールの作成を受注していて、クラウドワークスでは気が付けば100件以上のお仕事を受注してきました!
会社員をやりながらの副業なので時間の捻出は相応ですが、クライアントの方々と近い立場でこちらからも提案しながら活動していますのでお悩みあれば是非ご相談ください






















コメント