
Seleniumを使うときに一番よく使うのが、find_element / find_elementsですよね
ブラウザを自動操作するためには、画面上のボタンや入力欄を「どうやって特定するか」が重要ポイントです
まずは要素検索の基本
まずはよくある基本の書き方です
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com")
element = driver.find_element(By.ID, "username")このようにBy.IDやBy.NAMEなどを使って要素を探します
でも、このByの選び方によってコードの安定性や書きやすさが全然変わってきます
Byの種類とそれぞれの特徴
Byの種類は実は結構な数ありましてこんな感じ
- By.ID
- By.NAME
- By.CLASS_NAME
- By.TAG_NAME
- By.LINK_TEXT
- By.PARTIAL_LINK_TEXT
- By.CSS_SELECTOR
- By.XPATH
ネットでは”By.ID”や”CLASS_NAME”も見かけますが、結論は”By.CSS_SELECTOR“を使っておけば間違いないです
XPATHが他唯一候補になりますが、CSS_SELECTORはスクレイピングで使う”Beautiful Soup”にも応用できますし、記述がすっきりしてわかりやすいのでCSS_SELECTORに軍配が上がります
CSS_SELECTORが最適な理由
CSS_SELECTORが最適な最大の要因は全てCSS_SELECTORで代用できるところにあります
つまり、CSS_SELECTORさえ覚えてしまえば他を使う必要がなくなるんです
CSS_SELECTORでの代用方法
ここからは具体的に代用する際の記述です
Seleniumを利用するなら何度も書くことになる必修レベルなのでぜひ覚えてください
※説明は割愛しますが、XPATHも他の代用ができますので参考までに記載しておきます
driver.find_element(By.ID, ‘hoge’)
driver.find_element(By.CSS_SELECTOR, ‘#hoge’)
driver.find_element(By.XPATH, ‘//*[@id=”hoge”]’)
driver.find_element(By.CLASS_NAME, ‘hoge’)
driver.find_element(By.CSS_SELECTOR, ‘.hoge’)
driver.find_element(By.XPATH, ‘//*[@class=”hoge”]’)
driver.find_element(By.LINK_TEXT, ‘hoge’)
next((a for a in driver.find_elements(By.CSS_SELECTOR, ‘a’) if a.text == ‘hoge’), None)
driver.find_element(By.XPATH, ‘//a[text()=”hoge”]’)
driver.find_element(By.PARTIAL_LINK_TEXT, ‘hoge’)
next((a for a in driver.find_elements(By.CSS_SELECTOR, ‘a’) if ‘hoge’ in a.text), None)
driver.find_element(By.XPATH, ‘//a[contains(text(), “hoge”)]’)
driver.find_element(By.TAG_NAME, ‘div’)
driver.find_element(By.CSS_SELECTOR, ‘div’)
driver.find_element(By.XPATH, ‘//div’)
driver.find_element(By.NAME, ‘hoge’)
driver.find_element(By.CSS_SELECTOR, ‘[name=”hoge”]’)
driver.find_element(By.XPATH, ‘//*[@name=”hoge”]’)
driver.find_element(By.CSS_SELECTOR, ‘[data-test=”hoge”]’)
driver.find_element(By.XPATH, ‘//*[@data-test=”hoge”]’)
driver.find_element(By.CSS_SELECTOR, ‘div.hoge.piyo’)
driver.find_element(By.XPATH, ‘//div[contains(@class, “hoge”) and contains(@class, “piyo”)]’)
親子要素、兄弟要素を指定
もう一つCSS_SELECTORの大きな利点として親子要素、兄弟要素の指定ができるところです
親子要素、兄弟要素とはHTMLソースで見たときに縦・横の関係にある要素です
- 親子 … 横(階層の深さ)
- 兄弟 … 縦(同じ階層の横並び)

例えば上図で黄色囲いした”説明文2です“の要素を指定しようとした時
driver.find_element(By.CLASS_NAME, "description")では上部の”説明文です“の要素を取得してしまいます※n番目の指定もできますがややこしくなるので割愛
うまく取得するためには指定が一意になるように親要素から指定する必要があり、どこまで丁寧に書くかですが
- “.younger .description”
- “.younger > .card > .description”
- “div.younger > div.card > p.description”
などで取得できます
※このページ下部に同じ画像とソースを準備していますので試してみてください
親子要素、兄弟要素を指定するセレクタのいろいろ
要素を指定する方法はいくつかありまして状況に合わせて使い分けが必要です
| セレクタ | 意味 |
|---|---|
| A B(AとBの間にスペース) | Aの子孫であるB(何階層先でもOK) |
| A > B | Aの直下の子要素B |
| A + B | Aの直後の兄弟要素B |
| A ~ B | Aの後に続く兄弟要素B全て |
| A * | Aの後に続く全要素 |
| A , B | A or B |
| A > B, C > D | “A> B” or “C >D” ※”A> C >D” or “A > B > D”じゃない |
特に多く利用するのが上二つの親子要素を指定するセレクタです
開発者ツールでセレクタを自動判別
慣れてしまえばソースを見て起点とする要素の判別とそこから取得したい要素を導くセレクタが判断できるようになりますが、開発者ツールを使えば自動判別してくれます
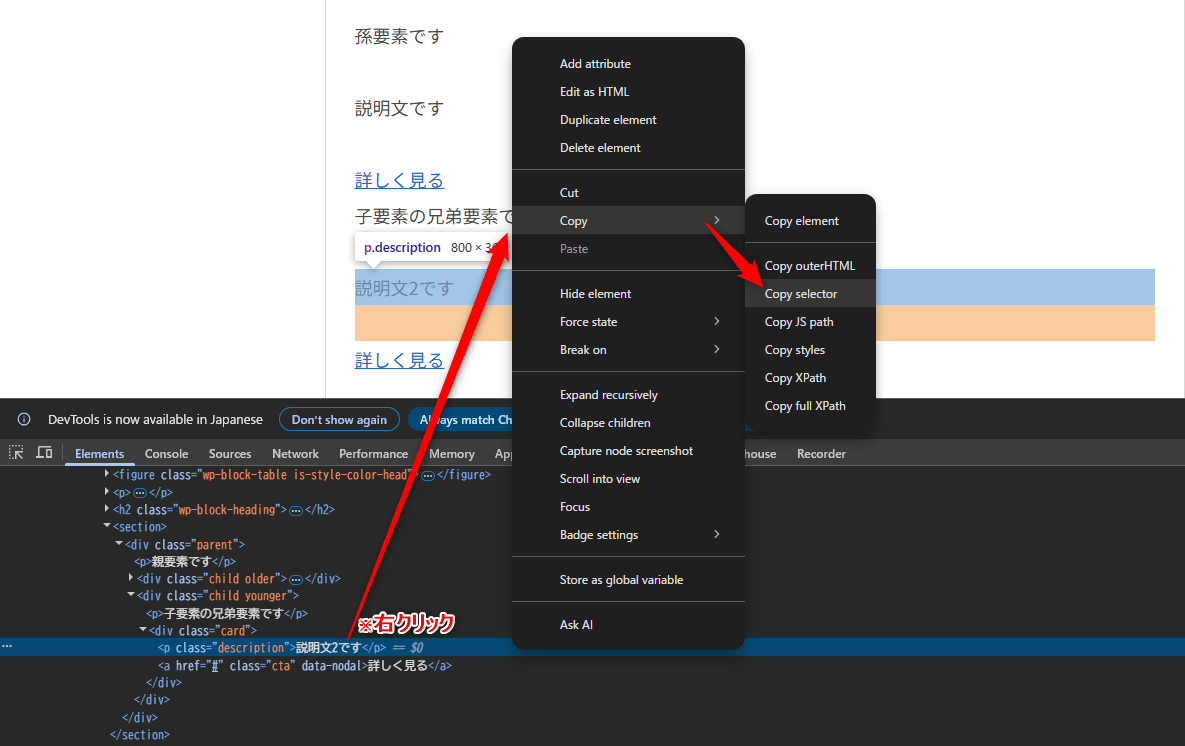
そのまま使うことは少ないですが、参考にするとか下書きで取得してそこから編集するには使える機能です
find_elementでよくあるエラーと回避方法
Seleniumを触っていると必ず出会うエラーが「NoSuchElementException」や「ElementNotInteractableException」
要素が見つからなかったり、まだ読み込みが終わってないのが原因です
例えば画面上の文字を取得しようとした時のプログラムは
hoge = driver.find_element(By.CSS_SELECTOR, '#hoge').textですが、これではもし指定した要素が見つからなかった場合にエラーになります
それを防ぐためには下記2パターンのどちらかを推奨です
# 10秒待っても要素が見つからないエラーをキャッチする
try:
elm = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#hoge')))
hoge = elm.text
except TimeoutException:
print('#hoge が見つかりませんでした')
except Exception:
print('予期せぬエラーが発生しました')# 要素が見つからないとNoneを返す
elm = next((e for e in driver.find_elements(By.CSS_SELECTOR, '#hoge')), None)
if elm:
hoge = elm.text
else:
print('#hoge が見つかりませんでした')やり方は違いますが”まずは要素を検索”した後に”目的のアクションを実施”することでエラーを防ぎます
このやり方なら文字の取得だけでなく、文字入力やクリックなどにも流用できます
あとがき
基礎の基礎なfind_elementでも結構奥が深いです
少しずつ理解を深めてSeleniumを活用していきたいですね
最後に練習に使えるHTMLを準備していますのでご自由にどうぞ

コメント