
いきなりですが、正規表現って暗号にしか見えず拒否反応が出るのって私だけですか?
VBAで部分一致してるかとかならLike演算子使えばいいし、文字を抜き出すならLeft、Right、MidにInstr、InstrRevとかを組み合わせれば大抵のパターンは対応できるので目を背け続けてきましたが、先日どうしても正規表現を使わざるを得ないことになって最低限使える程度には覚えたので書き出します
そもそも正規表現とは
正規表現は、文字列の集合を一つの文字列で表現する方法の一つである。
もともと正規表現は形式言語理論において正規言語を表すための手段として導入された。
その後正規表現は単機能の文字列探索ツールやテキストエディタ、ワードプロセッサなどのアプリケーションで、マッチさせるべき対象を表すために使用されるようになり、表せるパターンの種類を増やすために本来の正規表現にはないさまざまな記法が新たに付け加えられた。このような拡張された正規表現には正規言語ではない文字列も表せるものも多く、ゆえに正規表現という名前は実態に即していない面もあるが、伝統的に正規表現と呼ばれ続けている。
https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE
平たく言えばパターンマッチングってやつですね
このパターンの作り方が英字数字だけではなく記号も入り乱れているから暗号のような印象を受けるわけで、一見しても意味が分からないから拒絶反応が出るわけです
基本的な正規表現
まず基本的な正規表現の文字(メタ文字)から
| 文字 | 説明 |
|---|---|
| . | 任意の1文字(改行除く) |
| * | 直前のパターンの0回以上の繰り返し※最長一致 |
| + | 直前のパターンの1回以上の繰り返し※最長一致 |
| ? | 直前のパターンが0回または1回現れる※最長一致 |
| *? | 直前のパターンの0回以上の繰り返し※最短一致 |
| +? | 直前のパターンの1回以上の繰り返し※最短一致 |
| ?? | 直前のパターンが0回または1回現れる※最短一致 |
| () | ()内をグループ化する |
| | | いずれかの条件(つまりor) |
| [] | []内のいずれかの文字にマッチする |
| [^] | []内のいずれかの文字にマッチしない |
| {n} | 直前のパターンのn回繰り返し |
| {n,m} | 直前のパターンのn回以上、m以下の繰り返し ※nかmの一方を省略可 |
| \ | 直後のパターンが正規表現ではなくただの文字として扱うようにする(いわゆるエスケープ) |
| ^ | 先頭 |
| $ | 末尾 |
補足
サンプルに対して実際に正規表現のマッチ結果を補足的に書いてみる
abcde0edcba1AAAAA2BBB3あいうえお4\5カキクケコ
“最長一致”と“最短一致”の違いは最後にマッチする文字か最初にマッチする文字かの違い
| 正規表現 | 説明 | マッチ結果 |
|---|---|---|
| .*c | 最長一致 | abcde0edc |
| .*?c | 最短一致 | abc |
“(|)”と“[]”の違いは単語ベースで検索するか1文字単位で検索するか
| 正規表現 | 説明 | マッチ結果 |
|---|---|---|
| (bcd|dcb) | 単語で検索できる | bcd,dcb |
| [bcd] | 1文字単位で検索 | b,c,d |
| (b|c|d) | 全て1文字なので[bcd]と同じ | b,c,d |
“[]”内は“-“で繋ぐことで範囲検索できる
| 正規表現 | 説明 | マッチ結果 |
|---|---|---|
| [a-z] | 「a~z」の小文字英字 | a,b,c,d,e |
| [B-F] | 「B~F」の大文字英字 | B |
| [0-9] | 「0~9」の数字 | 0,1,2,3,4,5 |
| [あ-ん] | 「あ~ん」のひらがな | あ,い,う,え,お |
| [^a-zB-F0-9あ-ん] | 上記以外 | A,\,カ,キ,ク,ケ,コ |
| A{3} | Aの3回繰り返し | AAA |
エスケープすると例えば“.”はドット扱いになるのでメアドとのマッチとかで使える
| 正規表現 | 説明 | マッチ結果 |
|---|---|---|
| \.*c | .がドット扱いになっている | c |
| \\ | \をエスケープする時は並べる | \ |
先頭と末尾を指定する機会はなくもないけど少ない気もする・・・
| 正規表現 | 説明 | マッチ結果 |
|---|---|---|
| ^bcd | 「bcd」はあるが先頭ではない | (なし) |
| bcd$ | 「bcd」はあるが末尾ではない | (なし) |
定義済みの正規表現
まず最初に「定義済み」って表現であってますか?(にわかです)
この定義済みの正規表現が便利そうな反面、難解になる原因な気がする
同等の正規表現があるものは無理して使う必要もないけど解読する時は知っておく必要があるのでよく使われるものだけ
他にもありますが私は頭の整理がつかなくなるこれだけにしてます
| 文字 | 説明 | 同等の正規表現 |
|---|---|---|
| \d | 数字 | [0-9] |
| \D | 数字以外 | [^0-9] |
| \w | 英字、アンダーバー、数字 | [a-zA-Z_0-9] |
| \W | 英字、アンダーバー、数字以外 | [^a-zA-Z_0-9] |
| \s | 空白 | [ \t\f\r\n] |
| \S | 空白以外 | [^ \t\f\r\n] |
| \t | タブ | (なし) |
| \r | 改行※キャリッジリターン | (なし) |
| \n | 改行※ラインフィード | (なし) |
VBAでの正規表現
まずは参照設定
「Microsoft VBScript Regular Expressions 5.5」にチェックを入れて利用できる状態へ

参照設定ではなくてCreateObjectを使うときは”VBScript.RegExp”
Dim objReg As Object
Set objReg = CreateObject("VBScript.RegExp")RegExpオブジェクトのプロパティとメソッド
| プロパティ | 説明 |
|---|---|
| Pattern | 正規表現のパターン |
| IgnoreCase | 大文字と小文字の区別しない時はTrue(指定しない場合はFalseが適用) |
| Global | 複数回マッチした場合2回目以降も取得するならTrue(指定しない場合はFalseが適用) |
| メソッド | 説明 |
|---|---|
| Test | マッチング結果をTrue、Falseで返す |
| Replace | マッチング成功した部分を置換する |
| Execute | マッチング結果をMatchCollectionオブジェクトで返す ※基本これを使う |
MatchCollectionのプロパティとメソッド
| プロパティ | 説明 |
|---|---|
| Count | マッチした件数を返す ※GlobalがFalseだと1が最大 |
| プロパティ | 説明 |
|---|---|
| Item | 指定したIndexのMatchオブジェクトを返す ※Match(Index)と同等 |
Matchのプロパティ
| プロパティ | 説明 |
|---|---|
| FirstIndex | 最初にマッチングした位置を返す ※文字列の先頭は0から |
| Length | マッチした文字列の長さを返す |
| Value | マッチした文字列を返す |
サンプルプログラム
私が正規表現を使うときは基本的にこの関数を準備して実行してます
Public Function RegExpFunc(Target As String, strPattern As String, Optional Idx As Long = 0, Optional strDelimiter As String = "") As String
'Dim objReg As New VBScript_RegExp_55.RegExp '---参照設定してればこれでもok
'Dim objMatchColl As VBScript_RegExp_55.MatchCollection '---参照設定してればこれでもok
'Dim objMatch As VBScript_RegExp_55.Match '---参照設定してればこれでもok
Dim objReg As Object
Dim objMatchColl As Object
Dim objMatch As Object
Set objReg = CreateObject("VBScript.RegExp")
With objReg
.Pattern = strPattern '---正規表現のパターン
.IgnoreCase = False '---大文字小文字の区別をする
.Global = True '---複数回マッチした場合は全て取得する
Set objMatchColl = .Execute(Target)
End With
'---Idxで指定したIndexのデータを取得する
RegExpFunc = vbNullString
If objMatchColl.Count > Idx Then
If Idx = -1 Then '---idxを-1でしていた時はobjMatchCollの結合モードにする
For Each objMatch In objMatchColl
RegExpFunc = RegExpFunc & strDelimiter & objMatch
Next
RegExpFunc = Replace(RegExpFunc, strDelimiter, "", 1, 1) '---先頭に余計なデリミタがあるから一度だけReplaceで削除する
Else
RegExpFunc = objMatchColl(Idx)
End If
End If
Set objMatch = Nothing
Set objReg = Nothing
End FunctionExcelでのテスト実行結果
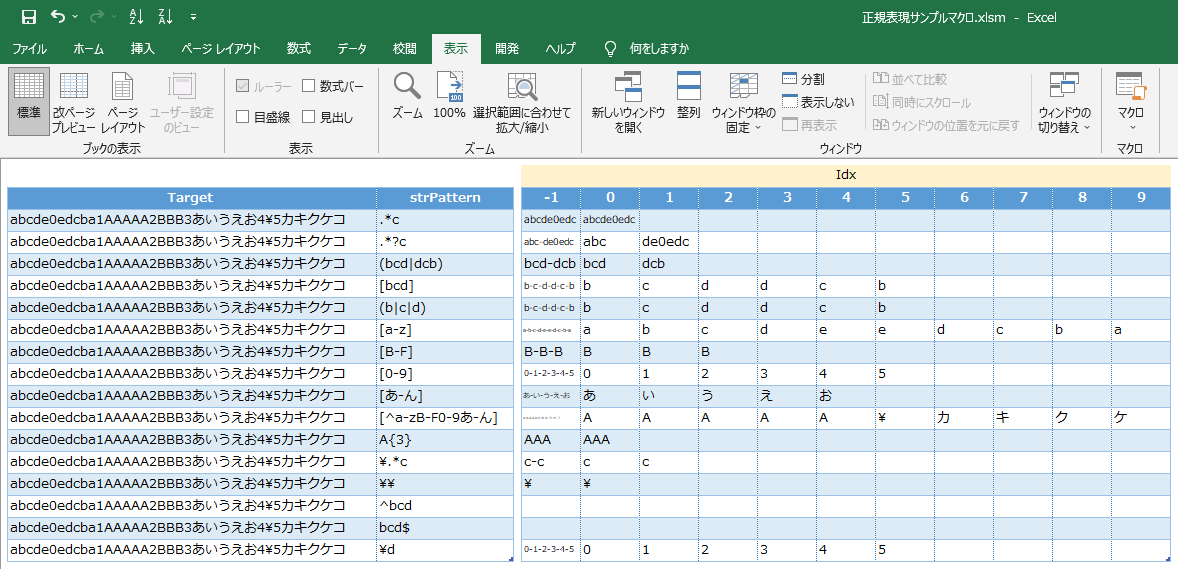
RegExpFuncを自作関数にして引数をヘッダー部の通りにした結果なのでまで参考に
実際のファイルは下記の”ダウンロード”ボタンを押下
よくある正規表現
| 名称 | 正規表現 | サンプル |
|---|---|---|
| 郵便番号 | \d{3}-\d{4} | 100-8111 |
| 携帯電話番号 | 0[789]0-\d{4}-\d{4} | 070-0123-4567 |
| 固定電話 | 0(\d-\d{4}|\d{2}-\d{3}|\d{3}-\d{2}|\d{4}-\d)-\d{4} | 03-3213-1111 |
| 日付 | \d{1,4}(/|-|年)([0-1]\d|\d)(/|-|月)([0-3]\d|\d)日? | 2022年08月17日 |
| ドメイン | ([a-zA-Z0-9][a-zA-Z0-9-]*[a-zA-Z0-9]*\.)+[a-zA-Z]{2,} | sub.example.co.jp |
あとがき
なんとなくは理解したものの、まだまだ奥は深いしここに書いていないメタ文字もあるので本職の人が書いてる正規表現は相変わらず意味が分からんです
正規表現チェッカーサイトも多々あるので必要ならちゃんと調べて覚えようかな


コメント