
Pythonでスクレイピングをする時にデータベースがあると色々楽でして、MySQL(MariaDB)やMicrosoft SQL Serverなど機能的にも優れたメジャーなデータベースを使うのもいいですが、個人利用かつ一時利用にはオーバースペック気味なのでお手軽使えるSQLiteの利用方法をご紹介します
“Pythonで使うため”前提なのであまり深堀はしませんが、シンプルかつ軽量なので初めてのデータベースにはオススメです
SQLiteとは
SQLiteはMySQL(MariaDB)やMicrosoft SQL Serverと同じでRDBMS(データベース管理システム)で、その名の通り軽量でオープンソースのデータベースです
と言っても特にサーバーなど準備する必要もなく、軽量なファイルがローカルに作成されるだけのお手軽データベース
SQLの知識が必要になりますが、最低限で十分なので覚えて損はないはず
SQLiteを利用するための準備
PythonはSQLiteを利用するためにはSQLite3を利用しますが、標準ライブラリ入っているので個別のインストールは不要で簡単に利用できます
必須ではないですが、GUIアプリの”DB Browser for SQLite”があると管理が楽になるので利用に合わせてお好みで
DB Browser for SQLiteのインストールについてはコチラのページからどうぞ

データ型
SQLiteもデータベースなのでデータ型が存在します
値としてのデータ型とカラムとしてのデータ型の2つの観点があって詳細を知りたいなら公式ページはコチラで、ざっくり書き出すと↓↓の通り
値のデータ型について
SQLiteの値は5種類だけで下記参照
| データ型 | 意味 |
|---|---|
| NULL | NULL値。 |
| INTEGER | 整数。1, 2, 3, 4, 6, or 8 バイトで格納。 |
| REAL | 浮動小数点数。8バイトで格納。 |
| TEXT | テキスト文字列。UTF-8, UTF-16BE or UTF-16-LEのいずれかで保存。 |
| BLOB | Binary Large OBject。入力データをそのまま格納。 |
他のデータベースでよくあるBool型、Date型はなく
- Bool型だと整数 0 (False) と 1 (True) で代替
- Date型は関数を使用してTEXT型なら(”YYYY-MM-DD HH:MM:SS.SSS”)、INTEGER型なら(1970-01-01 00:00:00 UTC からの秒数)として代替
カラムのデータ型について
続いてカラムで設定できるデータ型について
こちらも5種類だけでデータベースとしてはかなり少ないです
| 型親和性 | 説明 |
|---|---|
| TEXT | 基本は文字列として保存される |
| NUMERIC | 数値か文字列として保存される(基本は数値) |
| INTEGER | 数値として保存される(整数を優先) |
| REAL | 小数として保存される |
| BLOB | そのままのデータとして保存される(変換なし) |
なんですが、実際は指定したデータ型に関係なく値が保存出来ちゃいます
“SQLite.exe“でデータを見てみるとこんな感じ
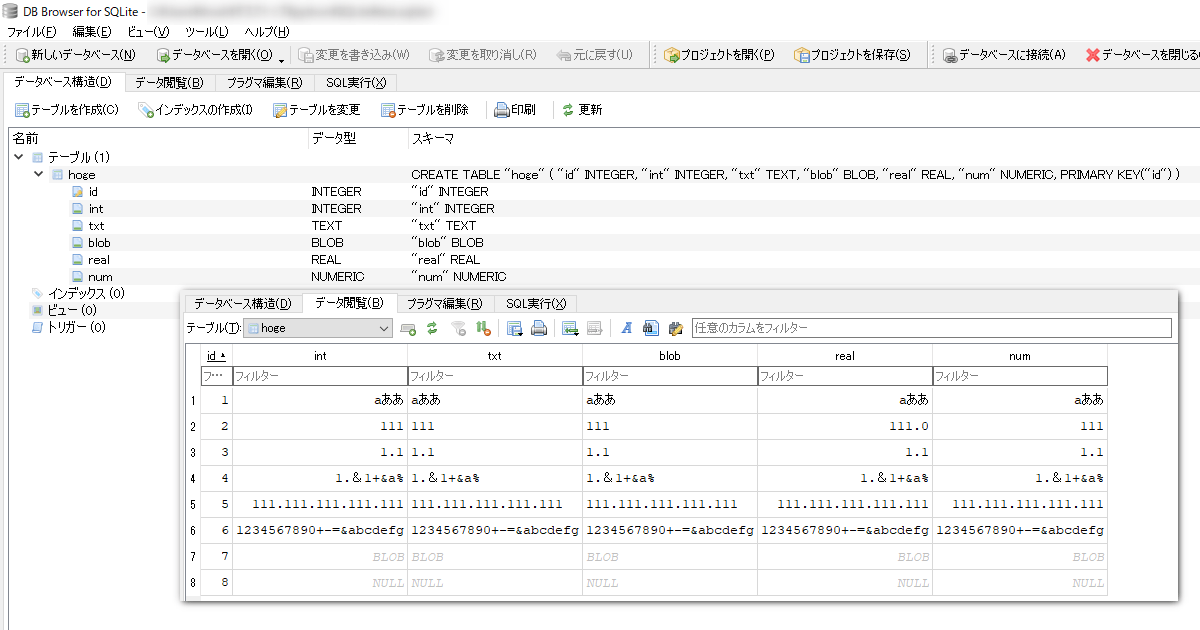
この仕様は良いのか悪いのか・・・
Pythonで実際に使ってみる
Pythonで使うと言っても基本的にはSQLを実行するだけ(データベースなんだからそりゃそう)
代表的なサンプルソース(≒SQL)を書き出します
db接続(≒ファイル作成)
DBの接続コマンドでファイルが無ければ生成してくれる
import sqlite3
# ---db接続(ファイルがなければ作成される)---
db_file= "test.sqlite3" # 拡張子は"*.db","*.sqlite","*.db3","*.sqlite3"からお好きなものを
conn = sqlite3.connect(db_file)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()テーブル削除と作成
SQLiteには“TRUNCATE TABLE”はないので“DROP & CREATE”で代替
“条件なしDELETE文”でも十分高速処理になるっぽい
# ---テーブルを作成---
# テーブルが既にあれば削除する
sql = "DROP TABLE IF EXISTS test_table"
cur.execute(sql)
# item_cdを主キーにテーブルを新規作成
sql = """
CREATE TABLE test_table(
item_cd INTEGER PRIMARY KEY,
item_name TEXT,
item_count INTEGER,
price INTEGER
)
"""
cur.execute(sql)
conn.commit() # コミットしないと反映しないデータの作成(挿入)
複数データを同時にINSERTする時は他のデータベースでは見ない処理方法
無理にまとめて処理しなくてもPythonの中でループ処理もありかも
# データを挿入 ※execute
sql = "INSERT INTO test_table (item_cd, item_name, item_count, price) VALUES (1, 'mouse', 1, 3000)"
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# まとめてデータを挿入 ※executemany
sql = "INSERT INTO test_table (item_cd, item_name, item_count, price) VALUES (?,?,?,?)"
data = [(2, "keyboard", 1, 8000), (3, "monitor", 1, 15000), (4, "USB cable", 3, 300), (5, "HDMI cable", 1, 1000)]
cur.executemany(sql, data)
conn.commit() # コミットしないと反映しないデータの取得
普通のSELECT文
取得データはレコードをTUPLE型、複数レコードはLIST型で取得できるのでforなどでループして取得してあげればOK
変数に格納するならexecute後にfetchallで値を取得できる
# データベースからデータを取得
sql = "SELECT * FROM test_table"
_ = cur.execute(sql)
rows = cur.fetchall()
for row in rows:
print(row)データの削除
特に変わりのない一般的な“DELETE文”
# データを削除
sql = "DELETE FROM test_table WHERE item_cd=1"
cur.execute(sql)
conn.commit() # コミットしないと反映しないデータの更新
こちらも一般的な“UPDATE文”
# データを更新
sql = "UPDATE test_table SET price=5000 WHERE item_name='keyboard'"
cur.execute(sql)
conn.commit() # コミットしないと反映しない同時に削除&挿入 or 挿入&更新
“REPLACE INTO”と“UPSERT(と同じような処理)”の両方使える
データベース的にはUPSERTの方が適切なんだけどREPLACE INTOの方が簡単
# データ削除と挿入を同時にする
sql = """
REPLACE INTO test_table (item_cd, item_name, item_count, price)
VALUES (3, 'wide monitor', 1, 30000)
"""
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# データ挿入時に重複なら更新する ※upsert文
sql = """
INSERT INTO test_table (item_cd, item_name, item_count, price)
VALUES (5, 'HDMI cable', 3, 800)
ON CONFLICT (item_cd)
DO UPDATE SET item_count=3, price=800
"""
cur.execute(sql)
conn.commit() # コミットしないと反映しない全部をまとめたサンプルソース
今までのプログラムを全部くっつけただけですが、実行すればSQLiteのプログラムを体感できるソースです
import sqlite3
# ---ファイルがなければ作成してdb接続---
db_file= "test.db" # 拡張子は".db"か".sqlite"
conn = sqlite3.connect(db_file)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# ---テーブルを作成---
# テーブルが既にあれば削除する
sql = "DROP TABLE IF EXISTS test_table"
cur.execute("DROP TABLE IF EXISTS test_table")
# item_cdを主キーにテーブルを新規作成
sql = """
CREATE TABLE test_table(
item_cd INTEGER PRIMARY KEY,
item_name TEXT,
item_count INTEGER,
price INTEGER
)
"""
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# データを挿入 ※execute
sql = "INSERT INTO test_table (item_cd, item_name, item_count, price) VALUES (1, 'mouse', 1, 3000)"
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# まとめてデータを挿入 ※executemany
sql = "INSERT INTO test_table (item_cd, item_name, item_count, price) VALUES (?,?,?,?)"
data = [(2, "keyboard", 1, 8000), (3, "monitor", 1, 15000), (4, "USB cable", 3, 300), (5, "HDMI cable", 1, 1000)]
cur.executemany(sql, data)
conn.commit() # コミットしないと反映しない
# データベースからデータを取得
sql = "SELECT * FROM test_table"
_ = cur.execute(sql)
rows = cur.fetchall()
for row in rows:
print(row)
# データを削除
sql = "DELETE FROM test_table WHERE item_cd=1"
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# データを更新
sql = "UPDATE test_table SET price=5000 WHERE item_name='keyboard'"
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# データ削除と挿入を同時にする
sql = "REPLACE INTO test_table (item_cd, item_name, item_count, price) VALUES (3, 'wide monitor', 1, 30000)"
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# データ挿入時に重複なら更新する ※upsert文
sql = """
INSERT INTO test_table (item_cd, item_name, item_count, price)
VALUES (5, 'HDMI cable', 3, 800)
ON CONFLICT (item_cd)
DO UPDATE SET item_count=3, price=800
"""
cur.execute(sql)
conn.commit() # コミットしないと反映しない
# 処理結果を見るためにもう一度データを取得
sql = "SELECT * FROM test_table"
_ = cur.execute(sql)
for row in cur.fetchall():
print(row)あとがき
CSVを直接書き出すプログラムだと重複チェックやスクレイピングで取得したデータを使った再スクレイピングが難しいのでデータベースが使えると幅が広がります
入門編としてSQLiteは導入コストはないし学習コストも少ないのでオススメです!


コメント