
AIに自分のPDFや社内ドキュメントを読ませて、その中身から回答してもらう機能、最近よく見るようになりましたよね
Claude Projects にファイルを投げたり、ChatGPT に PDF を渡したり、Notion AI で社内ページを横断検索したり、Perplexity に「最新の話題」を聞いたり、NotebookLM にノートを読み込ませたり、このあたりが全部、似た仕組みで動いています
その裏で動いているのが RAG(検索拡張生成)と呼ばれる仕組みです、名前は地味ですが、これを知っておくと AI製品の挙動が一気に腹落ちするので、押さえておいて損はないと思います
この記事で扱う範囲はざっとこんな感じです
- RAG が何の略でなぜ生まれたか
- 事前準備フェーズ + 実行時フェーズの2段階の動き方
- 精度を左右する「チャンク処理」の話
- 実際の製品事例と「最近聞かない理由」
- 自分で試す方法、ローカル/コスト面の話
- ハマりポイント・安全性・ファインチューニングとの比較
Claudeまわりの基本用語はClaudeを始める前に知っておきたい用語集でまとめているので、LLM や Embeddings あたりがピンと来ない方はそちらと並行して読むと入りやすいです
RAGとは何か 略称と必要になった理由
まずは言葉の意味と、そもそも何でこの仕組みが必要になったのか、というところから整理します
Retrieval-Augmented Generation の略
RAG は Retrieval-Augmented Generationの略で、日本語だと検索拡張生成と訳されます
各単語の意味をバラして見ると、もう少しイメージが湧きやすいかもしれません
| 単語 | 意味 |
|---|---|
| Retrieval | 検索・取り出し |
| Augmented | 拡張された・補強された |
| Generation | (文章の)生成 |
つなげると「外部から取り出した情報で補強された文章生成」になります、要するに AIが回答する前に、外部の情報を検索してから答える仕組みのことです
平たく言うと 「カンニング機能付きAI」と捉えるのが一番分かりやすいんじゃないでしょうか
カンニングと聞くとネガティブに響くかもしれませんが、ここでは「手元の資料を見ながら答える」くらいのニュアンスで、むしろ回答の正確性が上がる仕組みとして理解してもらえれば
そもそも生成AIには「知識のスナップショット問題」がある
なぜ RAG みたいな仕組みが必要になったかというと、生成AI(LLM)の知識は学習が終わった時点で止まっているからです
これは 「知識のスナップショット性質」とも呼ばれていて、学習データの締め切り日(カットオフ日)より後の出来事は本体だけだと知りません
正直に言うと私も最初これを実感していなくて、以前 ChatGPT に「去年あった有名なニュース」を聞いたら「すみません、その時期の情報は持っていません」と返ってきて、「あ、AIって本当に時間が止まってるんだ」と妙に感心した記憶があります
これに加えて、もうひとつ大きな壁があります
たとえ最新情報を学習させたとしても、あなたの会社の社内マニュアルや、あなたの個人ファイルは元から学習データに含まれていないので、本体だけで答えるのは原理的にむずかしいです
じゃあプロンプトに全部詰めて渡せばいいかというと、コンテキストウィンドウ(AIが一度に読める量)に上限があるのでこれも現実的じゃありません
そこで生まれた発想が 「都度、必要な情報だけ検索して渡す」というもので、これがまさに RAG の発想ベースになります
RAGには「事前準備」と「実行時」の2段階がある
ここから RAG の仕組みに入ります、ポイントは 2つのフェーズに分かれていることです
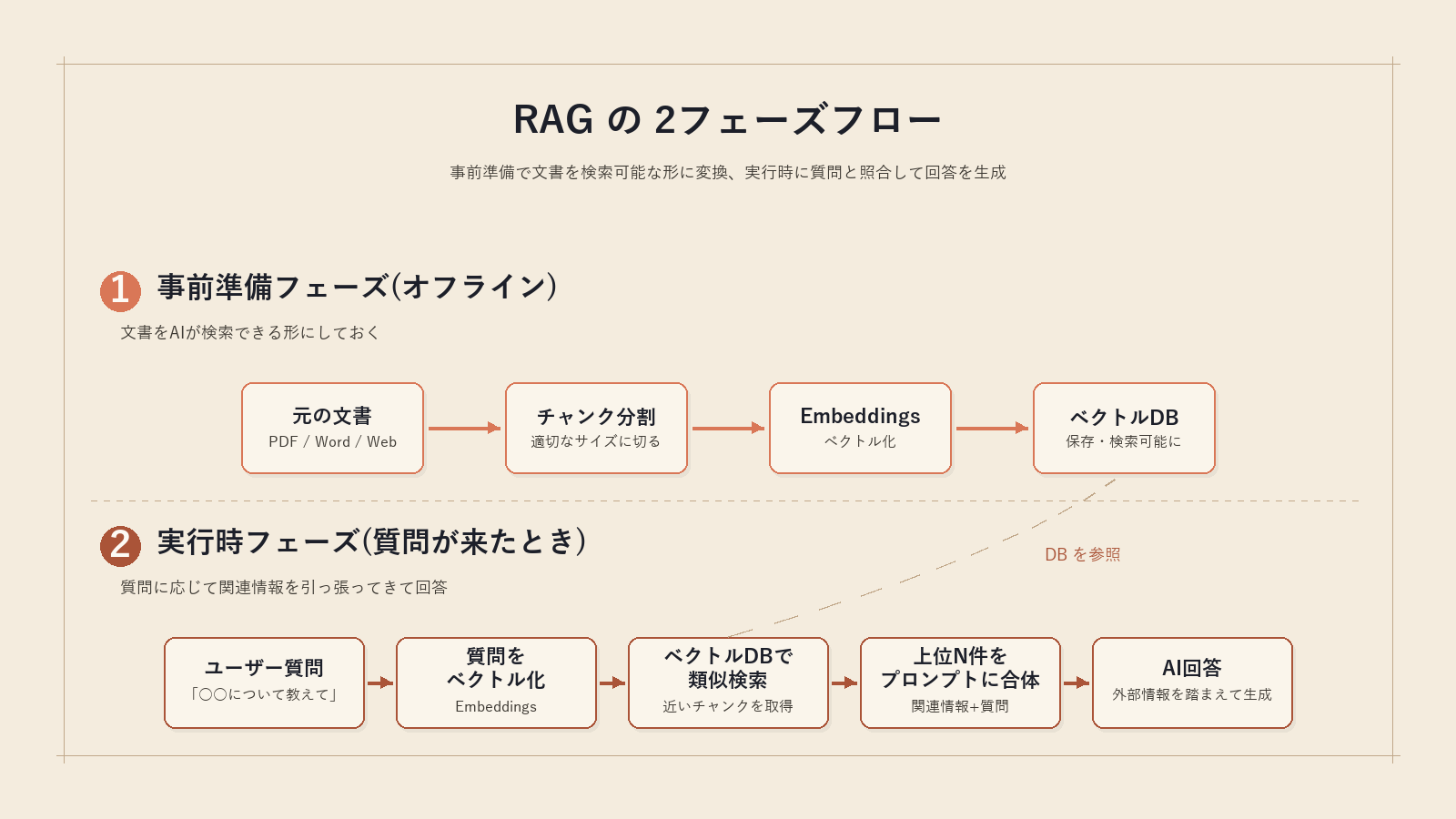
まずは事前準備フェーズ、これは 文書をAIが検索できる形に変えておく作業のことです
- 元の文書を取得(PDF / Word / Webページ / Notion / Slack ログなど)
- 文書を チャンク(かたまり)に分割する
- 各チャンクを Embeddings(埋め込み表現)でベクトル(数値の配列)に変換
- 変換結果を ベクトルDB(意味の近い文章を取り出すのに特化したデータベース)に保存
Embeddings は「文章を意味の似た方向に並ぶ数値に変換する処理」とイメージしておけばOKです、ここで 「意味が近い文章は近いベクトルになる」という性質を利用します
ベクトルDBは「意味の近さで文章を取り出すのに特化した専用データベース」のことです、ふだん使う MySQL のようなデータベースが文字列の完全一致や ID で引くのに対して、ベクトルDB は 近い意味の文章を効率よく見つけるのが得意です、有名どころでは Chroma・Pinecone・Qdrant・Milvus などがあります
続いて実行時フェーズ、これは 質問が来たら関連チャンクを引っ張ってきて回答に使う作業です
- ユーザーの質問も Embeddings でベクトル化
- ベクトルDBから意味が近いチャンクを検索
- 上位N件(3〜10件くらい)を取得
- 取り出したチャンクをプロンプトに合体させてAIに渡す
- AIが「渡された資料」をベースに回答を生成
つまり AI本体は最終的な文章生成だけ担当していて、その手前で 「カンペを取り出す処理」が裏で走っているのが RAG の本質、というわけです
事前準備フェーズで使うベクトル化と、実行時フェーズの質問のベクトル化は、原則として 同じ Embeddings モデルで揃えるのがコツです、ここがズレると意味の近さの判定がおかしくなります
チャンク処理がRAGの精度を決める
ここは中級者向けに少し厚めにいきます、結論から言うと RAG の精度はチャンク処理でほぼ決まると言っても言いすぎじゃないくらい大事なポイントです
なぜわざわざチャンクに分けるのか
「文書まるごと1つのベクトルにすればよくない?」と思うかもしれません
ただ、ベクトル検索は 短い単位の方が精度が出る性質があります、長すぎるテキストをまとめて1つのベクトルにすると、いろんな話題が混ざって「意味の中心」がぼやけてしまうためです
料理本まるごと1冊を1ベクトルにしても、「カレーの作り方」のような具体的な質問に対して効率よく該当ページを引っ張れません、適度な単位でバラしておく必要があります
チャンクサイズは大きすぎても小さすぎてもダメ
じゃあどのくらいの大きさで分割するのがいいか、というところですが、ここはトレードオフです
| チャンクサイズ | 起きやすいこと | 向いている用途 |
|---|---|---|
| 500字程度(小) | 文脈が切れる、前後の流れが拾えない | FAQ・短文の集まり |
| 1,500字程度(中) | 適度に意味が保てる、検索精度も出やすい | マニュアル・記事の本文 |
| 5,000字以上(大) | 無関係情報が混じる、意味がぼやける | 長文の章まるごとを参照したい場合 |
一般的な目安は 500〜1,000トークン(日本語で約1,000〜2,000文字)と言われていて、迷ったらこの範囲から始めるのがおすすめです
2026年現在の海外のベストプラクティス記事を見ても 「まずは 300〜500トークン + 10〜15% の重なり(オーバーラップ)から試そう」という推奨が多くて、実運用してから上下に振って調整する流れが主流ですね
チャンクオーバーラップで文脈ロスを防ぐ
分割するときによく使われるテクニックが チャンクオーバーラップです、隣り合うチャンクの端を少し重ねて分割します
たとえば 1,000字でチャンクを切るときに 100字くらい重ねておくと、文の途中で切れたときに前のチャンクの末尾と次のチャンクの先頭で同じ部分が読めるので、検索でどちらに引っかかっても文脈が補える、というのがメリットです
目立たないですが、これだけで 「PDFを入れたけど回答が変な感じで切れる」みたいな失敗が結構減ります
分割方法のバリエーション
チャンクをどう切るかは、文書の種類によって向き不向きがあります
- 固定文字数で切る:単純で実装しやすい、ただし文の途中で切れて意味が崩れることあり
- 改行や句読点で切る:文の途中で切れない、自然な単位になる
- 見出し単位で切る:Markdown や HTML で見出しが明確な文書に強い
- セマンティックチャンキング:Embeddings で意味の切れ目を判定して分ける賢い分割、精度は高いが計算コストもかかる
- 階層チャンキング:章の要約+詳細チャンクを両方持つやり方、長い技術文書で精度が出やすい
セマンティックチャンキングはかっこいい響きですが、素直な構造化文書なら固定 + オーバーラップで十分なことが多いです、海外でもいきなり凝った分割に手を出さず、シンプルな方法で品質が足りないと感じてから段階的に上げる、という推奨が増えています
日本語ならではの注意点
日本語のチャンク処理には、英語にはない少しクセがあります
英語はスペースで単語が区切られているので、機械的に「○○トークン単位で切る」のがやりやすいんですが、日本語はスペース区切りがないので 形態素解析(単語の切り分け)を併用したり、句読点や改行を頼りに分割したりすることが多いです
あと裏方ですが効いてくるのが文字数とトークン数の換算で、日本語は1文字あたり1〜2トークン消費するので、「500トークン = 約500〜1,000文字」くらいで見積もるのが安全です
このあたりは LangChain / LlamaIndex などのライブラリが日本語向けの分割関数を持っているので、自作するよりライブラリに任せる方がトラブルが少ない印象です
実際にどこで使われているか
仕組みの話が続いたので、ここで身近な製品でどこに RAG が使われているかを整理します、意外と毎日触っているサービスの中に隠れていますよ
代表的なRAG搭載サービス
- Claude Projects:プロジェクトにファイルを添付して質問、内部で文書を検索しながら回答
- ChatGPT カスタムGPTs / メモリ機能:添付資料・過去のやりとりを参照しながら応答
- Notion AI:社内ページや個人ノートを横断検索しながら回答するイメージで、まさに業務RAGの典型
- Perplexity:Web情報をその場で検索 → 結果を参照しながら回答するWeb検索型RAGの代表格
- NotebookLM:Googleが提供しているノート型AIサービス、PDFや音声などをノートに登録して質問
- Microsoft 365 Copilot:Officeの社内ファイル(Word・Excel・SharePoint等)を参照
共通点は 「AIが外部資料を参照して回答する」という点、つまり大半のサービスで裏側で RAG 的な処理が走っているということになります
個人用途だと、Claude Projects に1冊分のマニュアルを入れて「○○の手順は?」と聞く使い方は超実用的で、業務用途だと Notion AI で「先月の会議メモから決定事項だけ抜いて」みたいな雑な指示も通るようになっています
「RAG」という言葉、最近あんまり聞かない理由
余談ですが、2023年〜2024年あたりは「RAG構築」という言葉が AI 界隈で連発されていたんですが、ここ最近はわざわざ「RAGを使っています」と書くサービスが減っている印象があります
これは 技術が浸透して当たり前になったため、製品の中で言及しなくなったというのが大きいです、Webアプリを今わざわざ「これはWebアプリです」と言わないのと同じ現象だと思います
製品紹介では「ファイルから回答」「社内データを参照」「ノートを検索」みたいな機能名で呼ばれるようになっただけで、技術的な実体は大体 RAG です
「最近聞かない = 古い技術」と勘違いされやすいんですが、実態は逆で むしろ標準装備になったと捉えるのが正確ですね
もう一歩深く 自分でRAGを試す方法
仕組みが大体わかってきたら「自分でも触ってみたいな」と思うかもしれません、ここでは難易度別の選択肢と、コスト面・ローカル運用について整理します
3つの進化系キーワード
その前にもう少しだけ用語だけ紹介、RAG にも進化系がいくつかあって、覚えておくと最新の記事がだいぶ読みやすくなります
- Hybrid Search(ハイブリッド検索):キーワード検索とベクトル検索を組み合わせて精度を底上げする方式
- Re-ranking(リランキング):1次検索の結果を別のモデルで再評価して並べ替える、上位N件の精度を上げる
- Agentic RAG:AI が検索戦略そのものを判断するタイプ、「もう一回検索し直そう」「別の切り口で検索しよう」といった判断を AI 側に任せる
細かい挙動の違いを今すぐ理解する必要はなくて、「RAG にも進化形がいくつかあるんだな」くらいで頭の片隅に入れておけば十分です
手軽派 既製品RAGで試す
一番手っ取り早いのは既製品の RAG にファイルを入れてみるパターンです
- Claude Projects にPDFやMarkdownを投げる
- ChatGPT のカスタムGPTs でナレッジを設定する
- NotebookLM にPDF・YouTube URL・Webページを登録する
このパターンは「自分でチャンクを切る」「ベクトルDBを立てる」みたいな処理を全部サービス側が見えないところでやってくれるので、コードを1行も書かずに RAG を体験できます
仕組みを深く知りたいなら自作の方が学びは大きいですが、「とりあえず触感を掴みたい」だけならここから始めるのが現実的です
自作派 PythonライブラリでRAGを組む
もう一歩踏み込んで自分で組みたいなら、Python ベースのライブラリが定番です
- LangChain:RAG構築の総合フレームワーク、Embeddings/分割/ベクトルDB/プロンプトを一気通貫で扱える
- LlamaIndex:ドキュメントインデックスに強い、特に長文・多種類の文書を扱う用途で人気
- Haystack:検索パイプラインの構築に強い、エンタープライズ寄り
最小サンプルとしては「PDFを読み込んで分割 → OpenAI/Anthropic の Embeddings でベクトル化 → Chroma などのベクトルDBに保存 → 質問が来たら検索して回答」みたいな流れを Python で40〜60行くらいで書けます
ちなみに このコードを書くこと自体も Claude Code Desktop に頼めるので、最近は「自作派とは何だったのか」みたいな話になりがちです
コスト面 Embeddings API は意外と積む
自作 RAG を試すときに見落としがちなのが Embeddings API の呼び出し料金です
1回あたりは安いんですが、社内ドキュメントを全部ベクトル化しようとすると チャンク数 × Embeddings コストでじわじわ積み上がります、大規模な文書を扱う場合は事前見積もりが推奨です
加えて運用時の検索コスト(ベクトルDB のホスティング費)もかかるので、無料で動かしっぱなしというわけにはいかない、というのは知っておくと安心です
ローカルRAG OllamaやLM Studioで完結する選択肢
「API コストを気にせず、社外秘データもローカルで処理したい」というニーズには ローカルRAGという選択肢があります
Windowsユーザーなら次のあたりの組み合わせが現実的です
- Ollama:ローカルでLLM・Embeddingsモデルを動かす定番ツール、コマンド一発でモデルを起動できる
- LM Studio:GUIでローカルLLMを扱える、GGUF形式のモデルを試すならこっち
- ローカルベクトルDB:Chroma・Qdrant をローカル起動して使う
- ローカル Embeddings モデル:multilingual-e5・bge-m3 など日本語対応モデルを使う
動作は API 経由よりは遅いですし、性能もハイエンド商用モデルにはやや劣りますが、データを外に出さずに RAG が組めるのは大きいです、社内ナレッジを扱うユースケースでは選択肢として有力ですね
コードベース版RAG CursorやClaude Codeのインデックス
ちょっと毛色の違う話として、最近の開発者向けAIエディタにも RAG 的な仕組みが入っています
Cursor や Claude Code の コードベースインデックスと呼ばれる機能は、要するにプロジェクト全体のソースコードを RAG 的に検索可能な形に変換しておく仕組みです
AI が「この関数どこで使われてる?」と聞かれたとき、いきなりファイルを全部読まなくても、インデックスから関連箇所だけ引っ張って答えられる、という動き方ですね、これも広い意味で RAG の一形態と捉えていいと思います
Claude Code の各拡張機構(Skills・Hooks・Subagents など)を体系的に整理した話はClaude Code拡張機構入門の記事でまとめているので、開発寄りに興味がある方はそちらも合わせてどうぞ
ハマりポイントと安全性 RAGの限界も含めて
最後に実用面の話を一気にまとめます、RAG あるある・データの安全性・ファインチューニングとの違い、というあたりです
代表的な失敗パターンと対処法
初心者が RAG を試すと、ほぼ全員が同じところでつまずきます、典型例をまとめておきますね
| 症状 | 主な原因 | 対処の方向性 |
|---|---|---|
| PDFを入れたのに回答できない | PDF内の表や画像のテキスト化がうまくいっていない、チャンク処理がズレている | OCR や PDF パーサーを見直す、文書を事前に Markdown 化する |
| 期待ほど精度が出ない | チャンクサイズ・分割方法が文書と合っていない | サイズを上下に振ってテスト、オーバーラップを増やす |
| 同じ質問でも回答がブレる | 検索のヒット順がわずかな差で変わる、上位N件のチャンクが揺れる | Re-ranking を入れる、Top-K を上げる |
| コンテキストオーバーフロー | 大きすぎるチャンクを大量に渡してしまっている | チャンクサイズを下げる、上位N件を絞る |
| 関係ないチャンクが混じる | ベクトル類似度のしきい値が緩い、ノイズデータが多い | 類似度のしきい値を上げる、前処理でクリーニング |
とくに「PDFを入れたのに回答できない」は かなりの確率で PDF パース問題です、表が画像として埋め込まれていたり、二段組のレイアウトがあったりすると、テキスト抽出の時点で内容が崩れていて、後段のベクトル化もうまくいきません
裏ワザ的には PDFをいったん人間が読める Markdown に変換してから RAG に投入すると、精度が一段上がることが多いです、ここは地味な作業ですが効きます
機密データを入れていいの データの安全性
業務利用で気になるのが「社内データを RAG に入れて大丈夫?」という安全性の話です
- ローカル動作のRAG:データが外に出ない構成にできるので原則安全、機密データ向き
- クラウドサービス系:各社の 学習利用ポリシーとデータ保持期間を確認する
- 商用契約:Claude for Work / Enterprise などの法人プランは 原則として学習に使われない規約になっている
Anthropic の場合は ユーザーデータを既定では学習に使わない方針が明示されています、最新の方針は Anthropicのプライバシーポリシーページと Claudeプライバシーセンターに整理されているので、業務利用するときは目を通しておくのが推奨です
2026年に入って 消費者向けプラン(Free / Pro / Max)では学習利用を任意でオン/オフできるオプションが追加されました、デフォルトはオフですが、自分でオンにした覚えがないか設定画面で確認しておくと安心です
Claude Code Desktop を業務で使うときのセキュリティ全般の話はClaude Code Desktop初心者向けセキュリティの記事でも触れているので、合わせて読むと安心材料が増えると思います
RAGの限界 検索精度に全てが乗っかる
RAG は強力な仕組みですが、万能ではありません
最大の制約は 「検索でヒットしなかった情報は使えない」という点で、ベクトル検索が外すと回答も外します、つまり検索段階の精度がすべての品質を決めると言ってよくて、ここを軽視すると後段がいくら賢くても結果が出ない、という現象が起きます
あとは大量のチャンクの中から本当に必要な数件を見抜く能力が問われるので、文書数が増えるほど検索チューニングの難しさが上がります
RAGとファインチューニングの使い分け
もう一つの相補技術が ファインチューニングです、これは AI自体に追加学習をさせて、特定の用途や知識を埋め込む方式で、RAG とは別のアプローチになります
どっちを使うべきか、というのはよく聞かれるトピックなので、表で比較しておきます
| 観点 | RAG | ファインチューニング |
|---|---|---|
| 知識の保管場所 | 外部DB(参照型) | モデル本体(埋め込み型) |
| 更新コスト | 低い(文書を入れ替えるだけ) | 高い(再学習が要る) |
| 更新頻度 | 毎日でも可能 | 都度の学習コストがネック |
| 初期コスト | 低〜中 | 中〜高 |
| 運用コスト | 検索コスト+API利用 | 学習コスト+ホスティング |
| 得意な用途 | 頻繁に変わる情報、社内ナレッジ | 応答スタイル・固定知識・ドメイン特化 |
| 不得意な用途 | 応答スタイルの変更 | 最新情報の追従 |
整理すると、RAG = 知識を都度参照する・ファインチューニング = モデルに知識や癖を埋め込む、という違いになります
たとえば「自社の最新マニュアルを参照したい」なら RAG が向いていますし、「自社特有の口調で常に応答してほしい」ならファインチューニングが向きます、両者を組み合わせる構成も実用ではよくあるパターンです
まとめ RAGが分かると AI 製品の見え方が変わる
長くなったので、ポイントをぎゅっと再掲して締めます
- RAG は Retrieval-Augmented Generation の略、外部情報を 検索してから生成する仕組み
- LLM の知識は学習時点で止まっているので、最新情報や社内固有情報を扱うには外部参照の仕組みが要る
- 動きは事前準備フェーズ(文書→チャンク→ベクトル化→DB)と実行時フェーズ(質問→検索→上位N件→AI回答)の2段階
- 精度の鍵は チャンク処理、サイズ500〜2,000文字+10〜15%オーバーラップから始めるのがおすすめ
- Claude Projects / Notion AI / Perplexity / NotebookLM など身近なAI製品の裏側でだいたい動いている
- 自分で試すなら Claude Projects / NotebookLM が手軽、自作なら LangChain / LlamaIndex、ローカルなら Ollama + Chroma
- ハマりポイントは PDF パース問題・チャンクサイズ・検索精度、ファインチューニングとは役割が違う相補関係
RAG という言葉自体は技術が浸透して目立たなくなりましたが、知っていると「あ、これ裏でRAG動いてるな」と AI 製品の見え方が一段クリアになるはずです
関連用語についてはClaudeを始める前に知っておきたい用語集に「埋め込み」「コンテキストウィンドウ」「ファインチューニング」あたりがまとまっているので、AI記事を読むベース知識を補強したい方はぜひ覗いてみてください
長文にお付き合いいただきありがとうございました、それでは、よい AI ライフを







コメント