
📦 プライム30日無料体験を試す
当ブログはAmazonアソシエイト・プログラムの参加者です。Amazonのアソシエイトとして、適格販売により収入を得ています。
【Python】netkeibaをスクレイピングする-その1
趣味で競馬をやっている私、ジャベ雄です
ブラッドスポーツと呼ばれるほど血統が重要視されていたり、会場による傾向や枠の有利不利などデータがものを言う競馬界においてデータ収集先の代表格、netkeibaをPythonでスクレイピングする方法をまとめます
今回は”netkeibaをスクレイピングする”ことではなく、”netkeibaを題材にスクレイピングを学ぶ”ところに重きを置いているのでその前提で見てもらえると嬉しいです
目次
スクレイピングを始める前に
今回はnetkeibaから大量のデータを取得しますし、取得したデータは分析してナンボなので取得情報はデータベース(今回はXserverのMariaDB)に保存する前提でプログラム作成していますので必要に応じて適宜変更してください
PythonでXserverを操作する方法は↓↓を参考にどうぞ
https://javeo.jp/python-xserver-connect
一度手動で操作しながらURLやページを観察する
スクレイピングの初手はRPA的に情報取得すべきページへ遷移するところからです
一度手動で一連の動作を実施しながら特にURLに注目しながら観察すればパラメータを変更しながらページを読み込むのか、ボタンをクリックする必要があるのかなどがわかります
最初に静的ページか動的ページか確認する
Pythonでスクレイピングをする時の2台巨塔”Selenium“と”Beautifulsoup“ですが、どちらを使うかの切り分けはそのサイト(ページ)がJavascriptを有効にする必要があるかどうか
確認するためにははChromeの設定メニューで切り替えるのですが、頻繁に切り替える可能性がある人はChrome拡張機能(私はQuick Javascript Switcher)を使うこと推奨です
で、肝心のnetkibaはどうかと言うと開催レース一覧の画面がJavascript無効ではと永遠と馬が走っている状態になってしまうので有効にしておく必要があるとわかるのでSelenium必須

ぶっちゃけ、”Beautifulsoup“だけで完結するサイトは少ないので”Selenium“を使う前提でもOK
まずはレースマスタを作る(ベースの一覧を取得する)
私のスクレイピング方針のようなものですが最初は一覧情報を作ってその後に詳細情報を収集します
なぜかと言うとスクレイピングはNW状況含めて予想外にエラーが起こる可能性がありますし、詳細データでは予想外のデータもあるのでエラーが起こる前提として処理を途中から再開できるような仕様にすることが望ましいです
具体的にはnetkeibaなら開催日ごとのレース一覧、ECサイトなら検索結果画面にある商品ページリストを収集するイメージです
ここで”一度手動で操作しながらURLやページを観察する“に倣ってプログラムの方針を考えます
レース一覧を取得するために動作を確認する
まずは今週のレース一覧ページを開くとURLに”kaisai_date=yyyymmdd”がパラメータになっていることがわかるのでここを変更すれば良さそう
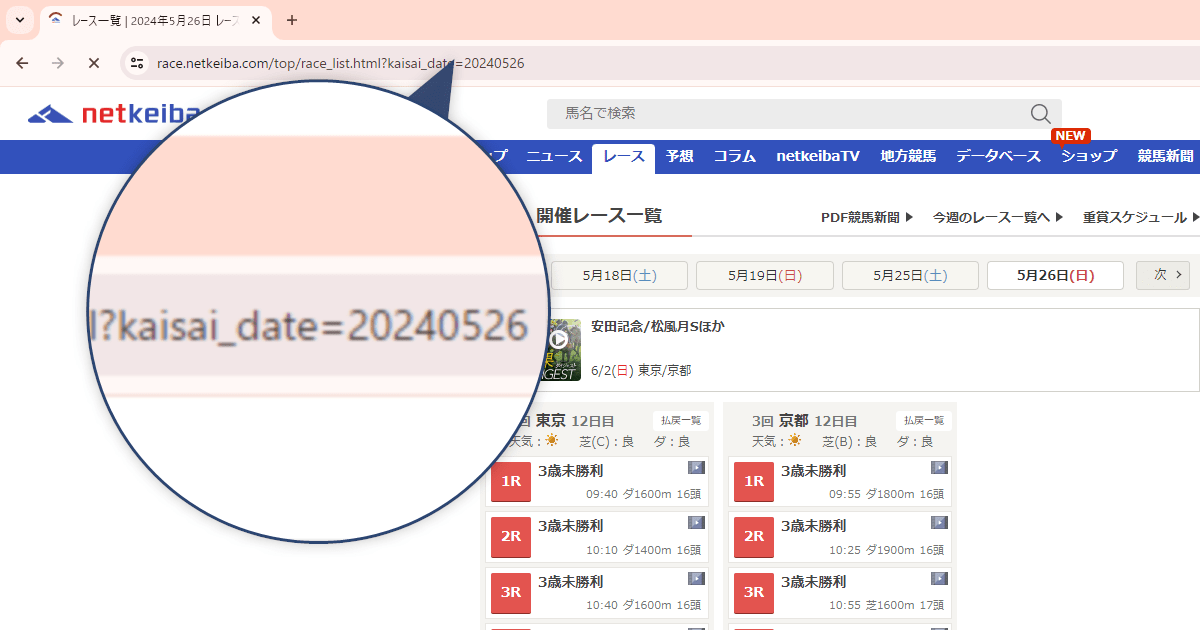
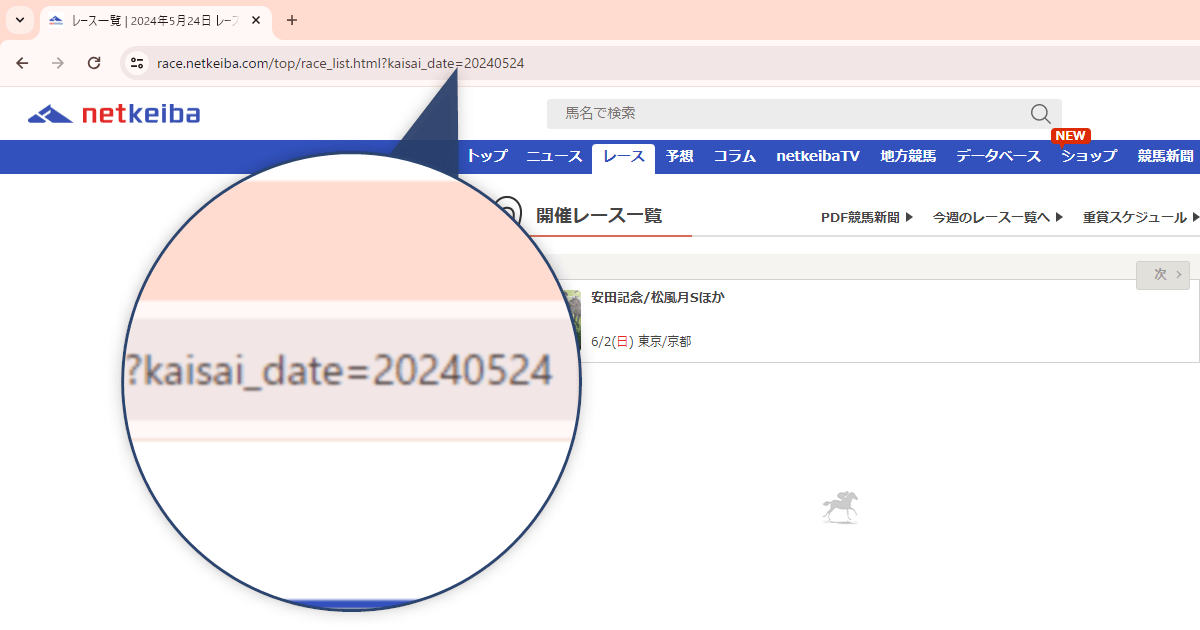
このパラメータを変えれば当然その日のレース一覧に変わるわけですが開催されていない日を指定するとレースが何も表示されないので1日ずる変更すると無駄な読み込みになってしまう
もう一つ、上部の”前”や”次”をクックすると1週間分の日付が前後することがわかります
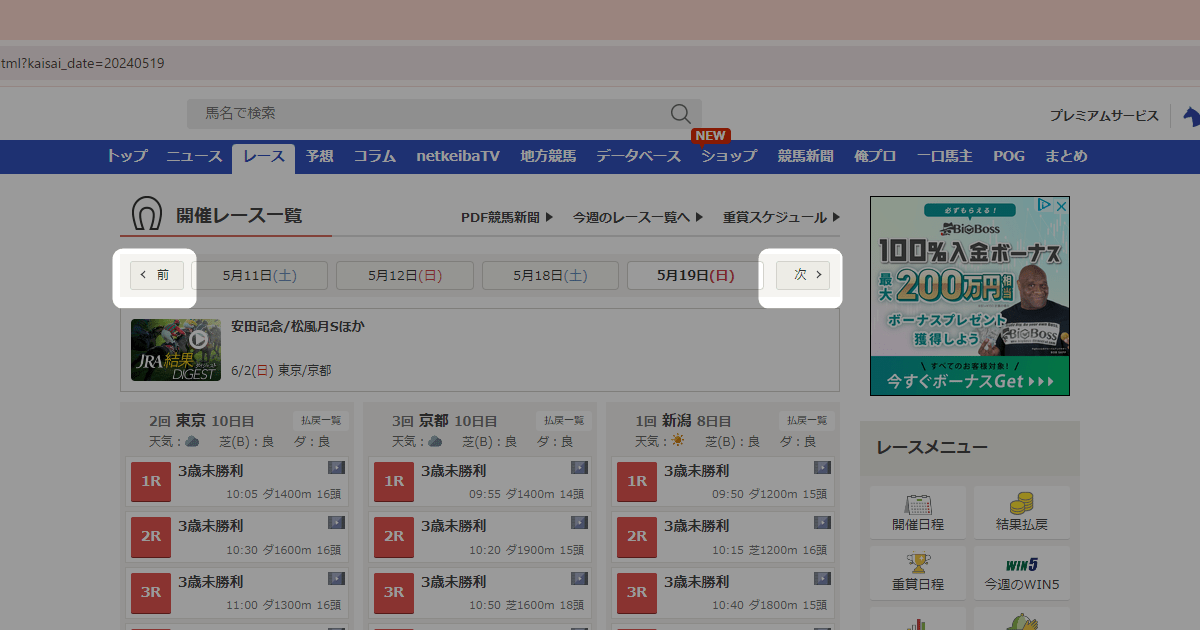
レース一覧を取得するための結論
楽をするなら最初のパターンで取得対象の日まで1日読み込めばいいんですが、なるべくサイトへ負荷をかけないように無駄なページロードを避けるためやめました
続いて土日だけにするとイレギュラー開催(土日以外)の情報がカバーできなので止めました
※イレギュラー開催→1月の金杯、年末のホープフル、3連休の月曜日開催など
結論、取得したい起点の日を表示した状態から”次”ボタンをクリックし続けて日付が当日以上になるまでループする仕様にしました
実際のプログラム
私が実際に使っているプログラムですが必要な項目は違うでしょうし、データベース操作用のプログラムも違うと思うので適当に変更してください
コメントを大量に残しているのでプログラム自体の説明は割愛
from datetime import datetime
import re
import urllib.parse
from time import sleep
from bs4 import BeautifulSoup
from db_connector import xserver_keiba
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
# ====================================================================================================
class data_class:
def __init__(self, data_title: list) -> None:
self.race_id = ''
self.race_date = ''
self.race_times = data_title[0]
self.course_place = data_title[1]
self.race_days = data_title[2]
self.race_no = 0
self.race_name = ''
self.race_grade = ''
self.race_time = ''
self.coruse_type = ''
self.course_distance = ''
self.not_found = 0
def upsert_sql(self):
sql = f'''
INSERT INTO race_mst(race_id,race_date,race_times,course_place,race_days,race_no,race_name,race_grade,race_time,coruse_type,course_distance,not_found)
values ({self.race_id},'{self.race_date}','{self.race_times}','{self.course_place}','{self.race_days}',{self.race_no},'{self.race_name}','{self.race_grade}','{self.race_time}','{self.coruse_type}','{self.course_distance}',{self.not_found})
ON DUPLICATE KEY UPDATE race_date='{self.race_date}',race_times='{self.race_times}',course_place='{self.course_place}',race_days='{self.race_days}',race_no={self.race_no},race_name='{self.race_name}',race_grade='{self.race_grade}',race_time='{self.race_time}',course_distance='{self.course_distance}',not_found='{self.not_found}'
'''.replace("''", "Null")
return sql
# ====================================================================================================
def grade_converter(grade_class) -> str:
# クラス名からレースのグレードを判定して返す
if 'Icon_GradeType1' in grade_class:
return 'GⅠ'
elif 'Icon_GradeType2' in grade_class:
return 'GⅡ'
elif 'Icon_GradeType3' in grade_class:
return 'GⅢ'
elif 'Icon_GradeType4' in grade_class:
return '重賞'
elif 'Icon_GradeType5' in grade_class:
return 'OP'
elif 'Icon_GradeType6' in grade_class:
return '1600万下'
elif 'Icon_GradeType7' in grade_class:
return '1000万下'
elif 'Icon_GradeType8' in grade_class:
return '900万下'
elif 'Icon_GradeType9' in grade_class:
return '500万下'
elif 'Icon_GradeType10' in grade_class:
return 'JGⅠ'
elif 'Icon_GradeType11' in grade_class:
return 'JGⅡ'
elif 'Icon_GradeType12' in grade_class:
return 'JGⅢ'
elif 'Icon_GradeType13' in grade_class:
return 'WIN5'
elif 'Icon_GradeType14' in grade_class:
return '特選'
elif 'Icon_GradeType15' in grade_class:
return 'L'
elif 'Icon_GradeType16' in grade_class:
return '3勝'
elif 'Icon_GradeType17' in grade_class:
return '2勝'
elif 'Icon_GradeType18' in grade_class:
return '1勝'
else:
pass
# ====================================================================================================
def main():
db = xserver_keiba()
# データベース内の最新レース日取得する
sql = '''
SELECT
MAX(race_date) AS last_get_date
FROM
race_mst
'''
ret = db.fetch(sql)
# dbにあるレース開催日の最大値を最初の取得対象日にする
# レースデータがない(≒初回)は'2014-01-05'で固定する
target_date = datetime(2014, 1, 5) if ret[0]['last_get_date'] is None else ret[0]['last_get_date']
options = Options()
# 画像を読み込まない
options.add_argument('--blink-settings=imagesEnabled=false')
# シークレットモードで起動
options.add_argument('--incognito')
# Chromeを起動する
driver = webdriver.Chrome(options=options)
# urlに日付を設定すれば対象日のレース画面になる
driver.get(f"https://race.netkeiba.com/top/race_list.html?&kaisai_date={datetime.strftime(target_date, '%Y%m%d')}")
sleep(0.5)
# 対象日付が未来日になるまでループする
while target_date < datetime.today():
next_date_tab = True
while next_date_tab is True:
next_date_tab = False
# ページソースをBeautifulSoupに食わせる
soup = BeautifulSoup(driver.page_source)
# 上部の日付のliにを確認
for race_date in soup.select('#date_list_sub > li[role="tab"]'):
# 上部の日付のliにあるdate属性から対象の日付を取得して未来日になったら終わらせる
if int(race_date.get('date')) >= int(datetime.now().strftime('%Y%m%d')):
break
# 取得済みの日付ならスキップ・未取得ならクリックする
sql = f'''
SELECT
*
FROM
race_mst
WHERE
race_date='{race_date.get('date')}'
'''
ret = db.fetch(sql)
if len(ret) > 0:
continue
else:
driver.find_element(By.CSS_SELECTOR, f'#date_list_sub > li[date="{race_date.get('date')}"]').click()
# ↑のクリックでソースが書き換わっているのでもう一度ページソースをBeautifulSoupに食わせる
soup = BeautifulSoup(driver.page_source)
# id="RaceTopRace"が複数ある可能性があるのでループさせる
for RaceTopRace in soup.select('#RaceTopRace'):
# 今表示されているRaceTopRaceは上の階層の属性で判断する
if RaceTopRace.parent.get('aria-hidden') == 'true':
continue
# 会場別でdlが分かれているのでループする
for dl in RaceTopRace.select('dl.RaceList_DataList'):
# レースごとにliが分かれてるからループする
for li in dl.select('dd.RaceList_Data > ul > li.RaceList_DataItem'):
# --- ここから実際のデータ取得 ---
# リンクが複数あるから'result.html'を含んでいるかで正誤判定する
for a in li.select('a'):
if 'result.html' in a.get('href'):
# 会場のヘッダー部から会場情報を取得する
data = data_class(dl.select_one('dt.RaceList_DataHeader > div.RaceList_DataHeader_Top > p.RaceList_DataTitle').get_text(separator='/', strip=True).split('/'))
# urlのクエリパラメータにレースIDがあるので分解する
url = a.get('href')
qs = urllib.parse.urlparse(url).query
qs_d = urllib.parse.parse_qs(qs)
data.race_id = qs_d['race_id'][0]
# --- a配下にレース情報があるので取得する ---
# レース番号
data.race_no = a.select_one('div.Race_Num.Race_Fixed > span').get_text(strip=True).replace('R', '')
# レース名
data.race_name = a.select_one('div.RaceList_ItemContent > div.RaceList_ItemTitle > span.ItemTitle').get_text(strip=True)
# レースのグレード設定があれば取得する
if len(a.select('div.RaceList_ItemContent > div.RaceList_ItemTitle > span.Icon_GradeType')) > 0:
data.race_grade = grade_converter(a.select_one('div.RaceList_ItemContent > div.RaceList_ItemTitle > span.Icon_GradeType').get('class'))
# 出走時刻
data.race_time = a.select_one('div.RaceList_ItemContent > div.RaceData > span.RaceList_Itemtime').get_text(strip=True)
# 障害レースはクラス設定がないので分岐
if len(a.select('div.RaceList_ItemContent > div.RaceData > span.RaceList_ItemLong')) > 0:
# 芝・ダートはクラスが設定されているからセレクタ―で指定する
data.coruse_type = a.select_one('div.RaceList_ItemContent > div.RaceData > span.RaceList_ItemLong').get_text(strip=True)[0]
data.course_distance = re.findall(R'\d+', a.select_one('div.RaceList_ItemContent > div.RaceData > span.RaceList_ItemLong').get_text(strip=True))[0]
else:
# 障害はクラスが設定されていないから苦肉でindex指定する
data.coruse_type = a.select('div.RaceList_ItemContent > div.RaceData > span')[1].get_text(strip=True)[0]
data.course_distance = re.findall(R'\d+', a.select('div.RaceList_ItemContent > div.RaceData > span')[1].get_text(strip=True))[0]
# レース日は変数から反映させる
data.race_date = race_date.get('date')
db.execute(data.upsert_sql())
next_date_tab = True
break
# 次ボタンを押すと次開催日に移るのでクリックする
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#nextBtn > a')))
except TimeoutException:
# 次がボタンになっていない(≒次がない)時はループを抜ける(けど、過去データしか取得しないから基本的にありえない)
break
driver.find_element(By.CSS_SELECTOR, '#nextBtn > a').click()
# 一瞬でもsleepしないと処理が早すぎてエラーになる可能性があるので0.5秒待機
sleep(0.5)
# クエリパラメータに開催日があるので日付型に変換する
qs = urllib.parse.urlparse(driver.current_url).query
qs_d = urllib.parse.parse_qs(qs)
target_date = datetime.strptime(qs_d['kaisai_date'][0], '%Y%m%d')
# 最後にChromedriverを落として終了
driver.close()
driver.quit()
# ====================================================================================================
if __name__ == '__main__':
main()
あとがき
プログラムはもう少しスマートに書いた方が良さそうですが問題なく動いているのでこの辺りで手打ちにしました
netkeibaのスクレイピングにはまだ先は長いですが第一歩のまとめでした
次はレース画面を収集する方法をまとめます!
最後に・・・
PythonとExcelを中心に仕事に役立つ業務ツールや自動化、スクレイピングツールの作成を受注していて、クラウドワークスでは気が付けば100件以上のお仕事を受注してきました!
会社員をやりながらの副業なので時間の捻出は相応ですが、クライアントの方々と近い立場でこちらからも提案しながら活動していますのでお悩みあれば是非ご相談ください











コメント